
 대표어
대표어
 한국학술지인용색인(NRF)
한국학술지인용색인(NRF)








권호기사보기
| 기사명 | 저자명 | 페이지 | 원문 | 기사목차 |
|---|
결과 내 검색
동의어 포함
목차
타언어권 화자 음성인식을 위한 혼잡도에 기반한 다중발음사전의 최적화 기법 / 김민아 ; 오유리 ; 김홍국 ; 이연우 ; 조성의 ; 이성로 1
〈Abstract〉 1
1. 서론 2
2. 음성 코퍼스와 Baseline 음성인식기 3
2.1. 음성 코퍼스 3
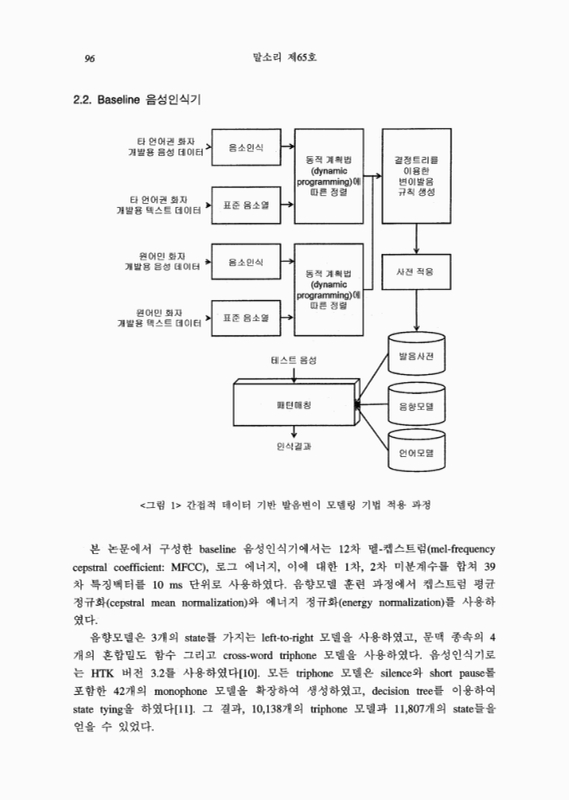
2.2. Baseline 음성인식기 4
3. 간접적 데이터 기반 타언어권 화자 발음변이 모델링 5
4. 제안된 발음사전 최적화 방법 5
4.1. 혼잡도 측정 방법 6
4.2. 혼잡도 측정을 통한 발음사전 최적화 8
5. 실험 및 결과 8
6. 결론 9
참고문헌 10
[저자소개] 11
| 기사명 | 저자명 | 페이지 | 원문 | 목차 |
|---|---|---|---|---|
| 영어 원어민과 한국어 원어민의 한국어운율 인식 | 이서배 | pp.1-11 |
|
보기 |
| 한국인과 한국어 학습자의 단모음 발화 | 김정아 ;김다히 ;이석재 | pp.13-36 |
|
보기 |
| 청각장애 성인 남성의 음성 특성 | 서경희 | pp.37-49 |
|
보기 |
| 자폐 범주성 장애아동과 정상아동의 평서문 읽기에서의 운율구 특성 비교 | 정금수 ; 성철재 | pp.51-65 |
|
보기 |
| 대각공분산 GMM에 최적인 선형변환을 이용한 강인한 화자식별 | 김민석 ;양일호 ;유하진 | pp.67-80 |
|
보기 |
| 파형보간 코더에서 파라미터간 거리차를 이용한 가변비트율 기법 | 양희식 ; 정상배 ; 한민수 | pp.81-91 |
|
보기 |
| 타언어권 화자 음성인식을 위한 혼잡도에 기반한 다중발음사전의 최적화 기법 | 김민아 ;오유리 ;김홍국 ;이연우 ;조성의 ;이성로 | pp.93-103 |
|
보기 |
| 한국어 음성인식을 위한 음성학 기반의 유사음소단위 집합 설계 | 홍혜진 ;김선희 ;정민화 | pp.105-124 |
|
보기 |
| 한국어 특성과 CRFs를 이용한 자동 띄어쓰기 시스템 | 이현우 ;차정원 | pp.125-141 |
|
보기 |
| TMS320VC5510 DSP를 이용한 AMR 음성부호화기의 실시간 구현 | 김 준 ;배건성 | pp.143-152 |
|
보기 |
| CASA 기반 음성분리 성능 향상을 위한 형태 분석 기술의 응용 | 이윤경 ; 권오욱 | pp.153-168 |
|
보기 |
| 번호 | 참고문헌 | 국회도서관 소장유무 |
|---|---|---|
| 1 | S. Goronzy, M. Sahakyan, W. Wokurek, “Is non-native pronunciation modeling necessary”, Proc. Eurospeech, Vol. 1, pp. 309-312, 2001. | 미소장 |
| 2 | J. Bellegarda, “An overview of statistical language model adaptation”, Proc. ITRW on Adaptation Methods for Speech Recognition, pp. 165-174, 2001. | 미소장 |
| 3 | I. Amdal, F. Korkmazsdiy, A. C. Surendran, “Data-driven pronunciation modelling for non-native speakers using association strength between phones”, Proc. ASRU, Vol. 1, pp. 85-90, 2000. | 미소장 |
| 4 | M. Kim, Y. R. Oh, H. K. Kim, “Non-native pronunciation variation modeling using an indirect data-driven method”, Proc. ASRU, Vol. 1, pp. 231-236, 2007. | 미소장 |
| 5 | M. Tsai, F. Chou, L. Lee, “Improved pronunciation modeling by properly integrating better approach for baseform generation, ranking and pruning”, Proc. ISCA Workshop on Pronunciation Modeling and Lexical Access (PMLA), pp. 77-82, 2002. | 미소장 |
| 6 | I. Amdal, F. Korkmazskiy, A. C. Surendran, “Joint pronunciation modelling of non-native speakers using data-driven methods”, Proc. ICSLP, pp. 622-625, 2000. | 미소장 |
| 7 | G. Hernandez-Abrego, L. Olorenshaw, R. Tato, T. Schaaf, “Dictionary refinements based on phonetic consensus and non-uniform pronunciation reduction”, Proc. ICSLP, pp. 551-554, 2004. | 미소장 |
| 8 | SiTEC의 공동 이용을 위한 음성 코퍼스 구축 현황 및 계획 | 소장 |
| 9 | 김봉완, 이용주, “음성정보기술산업지원센터의 음성 코퍼스 구축 현황 및 계획,” 한국음향학회 춘계 학술대회지, pp. 49-52, 2002. | 미소장 |
| 10 | S. Young, et al., The HTK Book (for HTK Version3.2), Microsoft Corporation, Cambridge University Engineering Department, 2002. | 미소장 |
| 11 | S. Young, J. Odell, P. Woodland, “Tree-based state tying for high accuracy acoustic modeling”, Proc. ARPA Human Language Technology Workshop, pp. 307-312, 1994. | 미소장 |
| 12 | http://www2.cs.uregina.ca/~dbd/cs831/index.html. | 미소장 |
| 13 | Binary codes capable of correcting deletions, insertions, and reversals  |
미소장 |
*표시는 필수 입력사항입니다.
| 전화번호 |
|---|
| 기사명 | 저자명 | 페이지 | 원문 | 기사목차 |
|---|
| 번호 | 발행일자 | 권호명 | 제본정보 | 자료실 | 원문 | 신청 페이지 |
|---|
도서위치안내: / 서가번호:

우편복사 목록담기를 완료하였습니다.
*표시는 필수 입력사항입니다.
저장 되었습니다.
