
 대표어
대표어
 한국학술지인용색인(NRF)
한국학술지인용색인(NRF)








권호기사보기
| 기사명 | 저자명 | 페이지 | 원문 | 기사목차 |
|---|
결과 내 검색
동의어 포함
목차
문장 분배기를 사용한 의존 구조 분석기 통합 / 이지민 ; 이진식 ; 이근배 1
요약 1
Abstract 1
1. 서론 1
2. 관련연구 2
2.1. 상태 변이 기반 의존 구조 분석 2
2.2. 그래프 기반 의존 구조 분석 2
2.3. 앙상블 모델 2
2.4. 스태킹 모델 2
3. 문장 분배하기 2
3.1. 개요 2
3.2. 문장 수준 분배기 3
3.3. 단어 수준 분배기 4
3.4. 문장 수준 분배기와 단어 수준 분배기의 비교 4
4. 실험 4
4.1. 문장 수준 분배기 4
4.2. 단어 수준 분배기 5
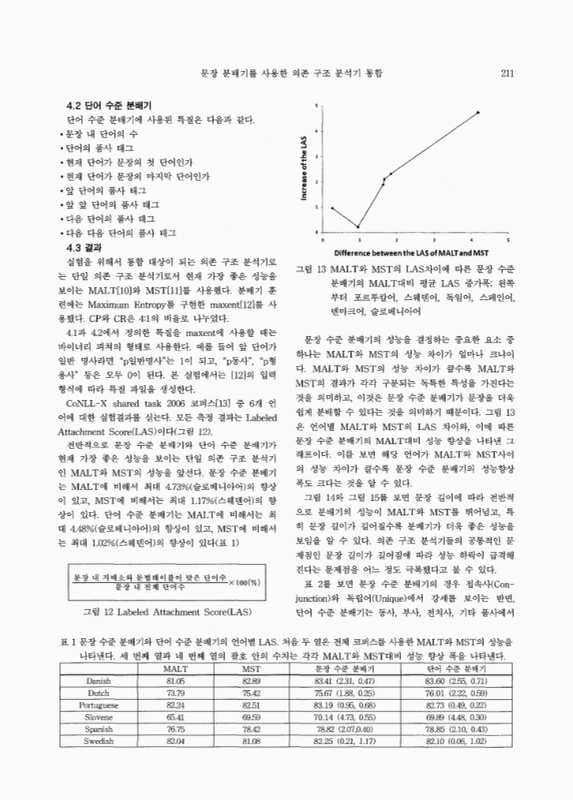
4.3. 결과 5
5. 토론 6
6. 결론 6
참고문헌 7
| 기사명 | 저자명 | 페이지 | 원문 | 목차 |
|---|---|---|---|---|
| 임베디드 소프트웨어에서 코드 리팩토링과 C 바운디드 모델 체커 도구의 적용 | 김성회 ,권기현 ,한혁수 ,이상은 ,이혁재 ,남일규 ,한주동 | pp.179-187 |
|
보기 |
| 공정제어 PLC응용SW의 재사용성과 유지보수성 향상을 위한 SW공학 원칙 적용사례 연구 | 양진석 ,김용수 ,강교철 | pp.188-197 |
|
보기 |
| 멀티 플랫폼에서 동작하는 일관된 모바일 어플리케이션 GUI 소스 코드 자동 생성 기법 | 류성태 ,박철현 ,이은석 | pp.198-206 |
|
보기 |
| 문장 분배기를 사용한 의존 구조 분석기 통합 | 이지민 ,이진식 ,이근배 | pp.207-213 |
|
보기 |
| 자질 가중치의 기계학습에 기반한 한국어 의존파싱 | 임수종 ,김영태 ,나동열 | pp.214-223 |
|
보기 |
| union 멤버 사용 오류 검출 기법 | 주성용 ,조장우 | pp.224-228 |
|
보기 |
| 번호 | 참고문헌 | 국회도서관 소장유무 |
|---|---|---|
| 1 | R. McDonald and J. Nivre, "Characterizing the errors of data driven dependency parsing models," Proc. of EMNLP-CoNLL, pp.122-131, 2007. | 미소장 |
| 2 | H. Yamads and Y. Matsumoto, "Statistical dependency analysis with support vector machines," Proc. of IWPT, pp.195-206, 2003. | 미소장 |
| 3 | J. Nivre, J. Hall, and J. Nilsson, "Memory-based dependency parsing," Proc. of CoNLL, pp.49-56, 2004. | 미소장 |
| 4 | J. M. Eisner, "Three new probabilistic models for dependency parsing: an exploration," Proc. of COLING, pp.340-345, 1996. | 미소장 |
| 5 | R. McDonald, K. Crammer, and F. Pereira, "Online large-margin training of dependency parsers," Proc. of ACL, pp.91-98, 2005. | 미소장 |
| 6 | K. Sagae and A. Lavie, "Parser combination by reparsing," Proc. of NAACL, pp.129-132, 2006. | 미소장 |
| 7 | J. Nivre and R. McDonald, "Integrating graph- based and transition-based dependency parsers," Proc. of ACL-HLT, pp.950-958, 2008. | 미소장 |
| 8 | A. F. T. Martins, D. Das, N. A. Smith, and E. P. Xing, "Stacking dependency parsers," Proc. of EMNLP, pp.157-166, 2008. | 미소장 |
| 9 | J. Lee, S. Jung, C. Lee, J. Lee, G. G. Lee, "Integrating two dependency parsers: picking the better one," Proc. of HCLT, 2009. (in Korean) | 미소장 |
| 10 | MALT 1.3.1 http://maltparser.org/ | 미소장 |
| 11 | http://sourceforge.net/projects/mstparser/ | 미소장 |
| 12 | http://www-tsujii.is.s.u-tokyo.ac.jp/~tsuruoka/maxent/ | 미소장 |
| 13 | S. Buchholz and E. Marsi, "CoNLL-X shared task on multilingual dependency parsing," Proc. of CoNLL, pp.149-164, 2006. | 미소장 |
| 14 | T. Kudo and Y. Matsumoto, "Japanese dependency analysis using cascaded chunking," Proc. of CoNLL, pp.1-7, 2002. | 미소장 |
| 15 | M. Iwatate, M. Asahara, and Y. Matsumoto, "Japanese dependency parsing using a tournament model," Proc. of COLING, pp.361-368, 2008. | 미소장 |
*표시는 필수 입력사항입니다.
| 전화번호 |
|---|
| 기사명 | 저자명 | 페이지 | 원문 | 기사목차 |
|---|
| 번호 | 발행일자 | 권호명 | 제본정보 | 자료실 | 원문 | 신청 페이지 |
|---|
도서위치안내: / 서가번호:

우편복사 목록담기를 완료하였습니다.
*표시는 필수 입력사항입니다.
저장 되었습니다.
