
 대표어
대표어
 https://www.nia.or.kr/site/nia_kor/ex/bbs/View.do;jsessionid=B1F1410B3B44A6A20DD1058EBED7F672.a40edfd9773606361118?cbIdx=82618&bcIdx=28999&parentSeq=28999&pageIndex=1&mode=&searchKey=&orderbyDiv=date
https://www.nia.or.kr/site/nia_kor/ex/bbs/View.do;jsessionid=B1F1410B3B44A6A20DD1058EBED7F672.a40edfd9773606361118?cbIdx=82618&bcIdx=28999&parentSeq=28999&pageIndex=1&mode=&searchKey=&orderbyDiv=date








권호기사보기
| 기사명 | 저자명 | 페이지 | 원문 | 기사목차 |
|---|
결과 내 검색
동의어 포함
표제지 1
목차 1
1. 연구 배경 및 필요성 3
2. 벤치마크 데이터셋이란? 5
3. 글로벌 주요 벤치마크 데이터셋 현황 및 특징 8
① 범용: LLM이 수행해야 하는 가장 기본적이고 공통적인 인지ㆍ언어 능력을 평가하는 벤치마크 9
② 도메인 특화: 특정 학문 및 산업 분야에서 요구되는 전문 지식과 문제 해결 능력을 평가하도록 설계 12
③ 목적 지향: 특정 기능 및 사용 목적을 중심으로 설계된 벤치마크 15
4. 국내 LLM 벤치마크 데이터셋 현황 및 과제 18
5. 국내 AI 활용 환경을 반영한 벤치마크 마련의 전략적 의미 20
6. 벤치마크 데이터셋 마련을 위한 정부의 전략적 역할 22
참고자료 24
[그림 1] 초거대 언어 모델(100억+파라미터 이상)의 연도별 출시 동향 3
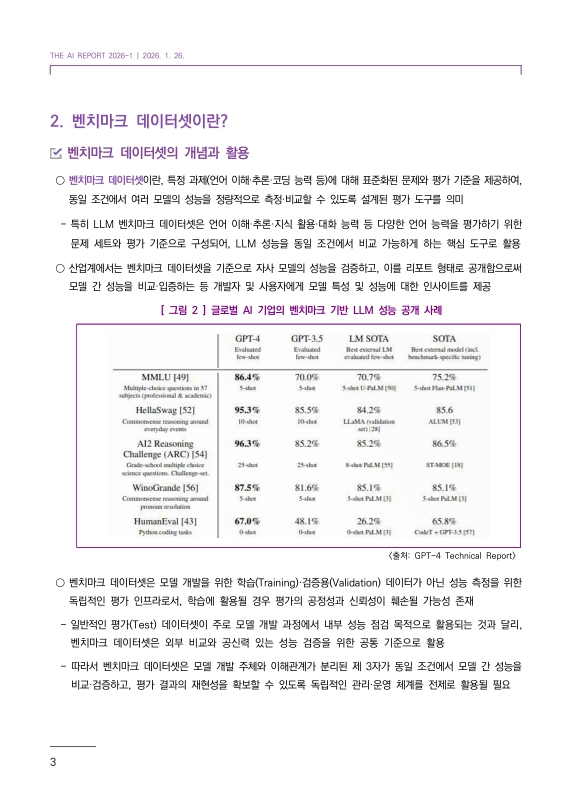
[그림 2] 글로벌 AI 기업의 벤치마크 기반 LLM 성능 공개 사례 5
[그림 3] 벤치마크 데이터셋을 활용한 평가 과정 6
[그림 4] 한국어 언어 모델 개발을 위한 민관 협력 체계(안) 22
*표시는 필수 입력사항입니다.
| 전화번호 |
|---|
| 기사명 | 저자명 | 페이지 | 원문 | 기사목차 |
|---|
| 번호 | 발행일자 | 권호명 | 제본정보 | 자료실 | 원문 | 신청 페이지 |
|---|
도서위치안내: / 서가번호:

우편복사 목록담기를 완료하였습니다.
*표시는 필수 입력사항입니다.
저장 되었습니다.
